LSTM(Long Short Term Memory networks),长短期记忆网络是经典RNN的升级版,原则上是RNN的一种。用来解决 long-term dependency问题,现被广泛使用。
Long-Term Dependencies
传统RNN的链式结构如下:

RNN最大优点就是能利用之前的信息来预测当前内容。比如要对句子 “云朵漂浮在天空” 的最后一个词“天空”进行预测。其实,光靠“云朵”这个词就能明显的知道预测词是“天空”。如下图,“云朵”和“天空”的位置是很近的。这样的操作在短文本里是比较有效实用的。

但是还有很多是长文本的预测。比如,“我 从小在中国长大,我很喜欢那里的美食……我能说很流利的中文。” 对这个长文本进行最后一个词“中文”的预测。根据附近的文字“说很流利的”,预测词很可能是一个语种,至于是什么语种还需要回归到最初的文本才能确定下来,如下图。然而这个预测词与最初的文本的距离可能是非常大的。
然而,预测词与相关文本的间距越大,RNN就越难去获取相关信息。这就是Long-Term Dependencies 问题。

因此就有了LSTM,来解决这个Long-Term Dependencies问题。
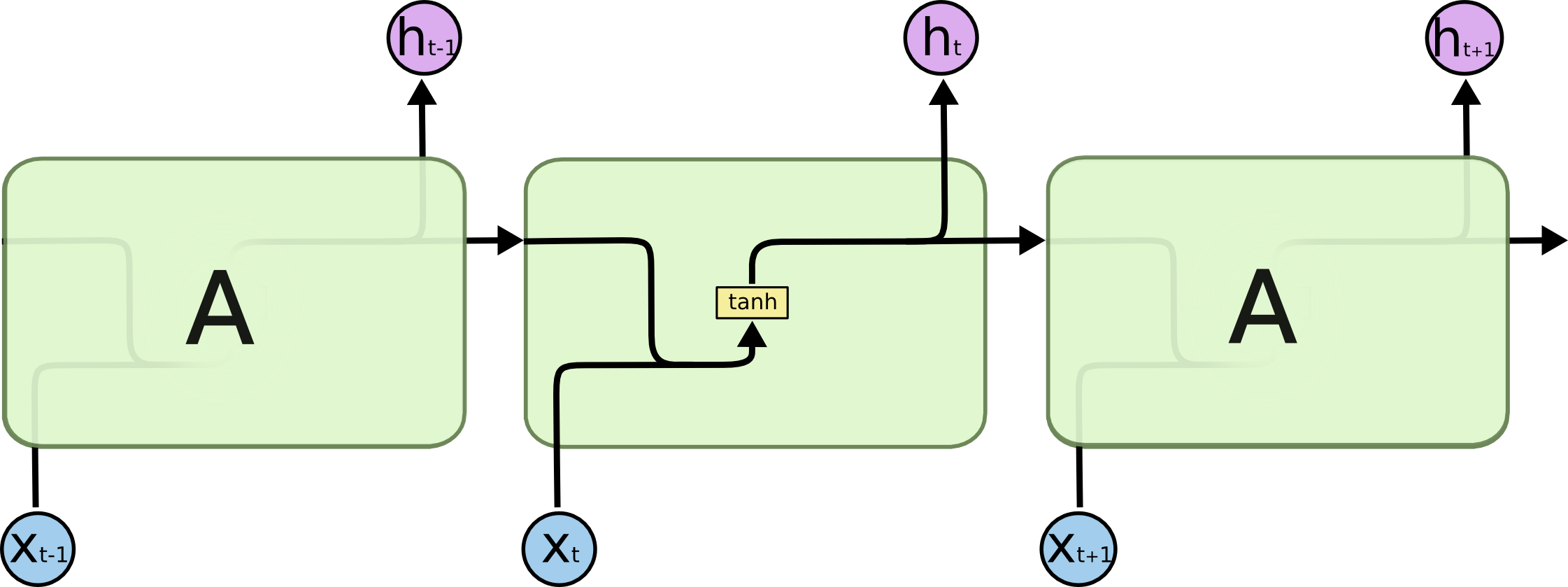
下面是传统的RNN的链式内部结构,很简单明了,比如有一个tanh层。
LSTM在大体上也是一个链式结构,但在内部稍做改进。与上面不同的是有4层网络结构。
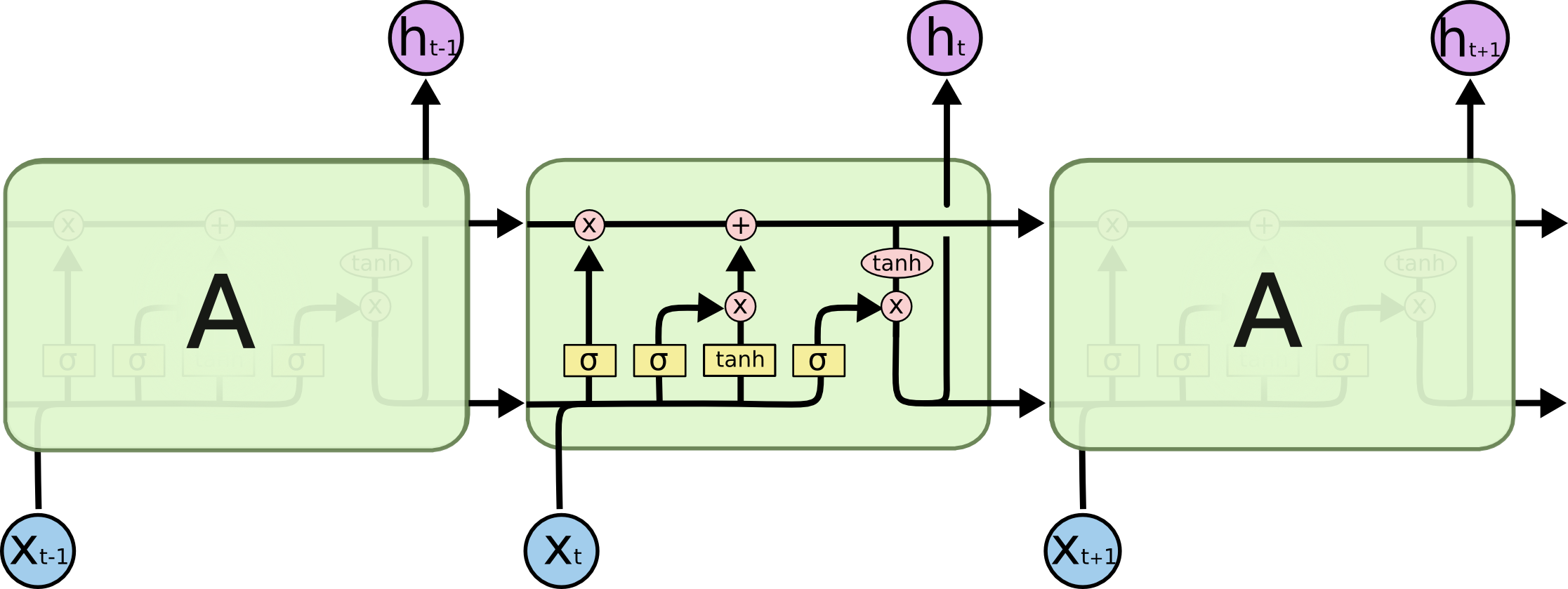
先不要觉得这个内部结构复杂,接下来会拆解开来一步步说明。下图是一些标记符号:

LSTM 核心结构
LSTM结构主线是下面的 → 的这条水平线。以下称为C线。这条线就像个传送带贯穿整个链式结构。这样使得信息流通且保全信息内容。

对于这条C线,LSTM本身没有删减文本信息的能力,信息量的删减是由各种“门”(gates)调控的。
门是对信息筛选的一种操作,有选择性的让信息流过。“门”由一个sigmoid层(a sigmoid neural net layer)和一个点乘组成(pointwise multiplication operation)。

- sigmoid层:输出为0-1的数,用来描述筛选信息的程度。0意味着不让信息流通,1意味着让所有信息流通。
- 一个LSTM有3个这样的门,来保护和控制这条C线上的信息流。
LSTM 拆解
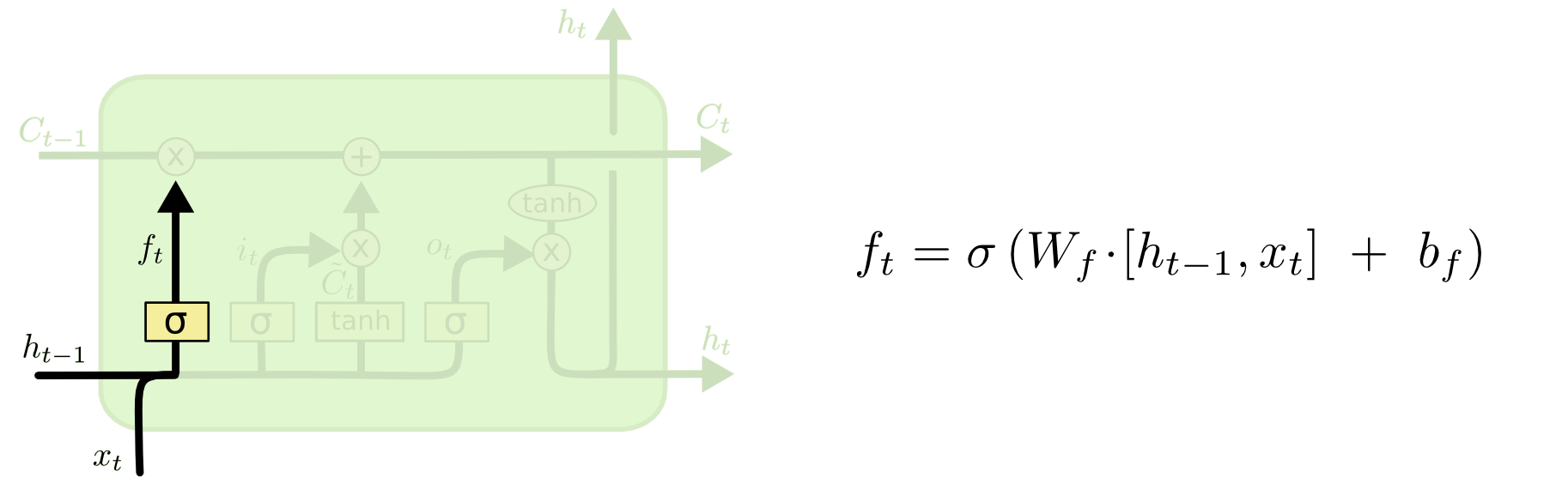
GATE 1
第一个门是用来决定在C线上丢弃哪些信息,由一个叫“forget gate layer”的sigmoid层构成,取决于和,它的输出是一个0-1的数值。比如在文本中,前一个句子的主角是个男性,后一个句子的主角是个女性,那么在前一个句子里获取的性别信息应该舍弃。
GATE 2
第二个门是用来确定保留哪些信息。这里由两部分组成,第一个是由一个叫“input gate layer”的sigmoid层来决定更新哪些数值,第二个是一个tanh层来创建一个候选C向量,这个向量可以被加到C线中。这两个的组合就形成了C线信息的更新。就像文本主角的性别信息更新。

GATE 3
现在来更新。是丢弃信息操作,是信息更新操作。这样就完成了主角性别信息的更新。

最后我们需要根据C线决定输出内容。首先是一个sigmoid层进行输出内容筛选。其次使其经过tanh处理再对sigmoid的输出进行点乘,就输出我们决定输出的内容。比如更新的是性别信息是一个名词,但预测词要求可能是一个代词,就需要进行将“男/女”信息转换成“他/她”的预测。

LSTM 变种
以上介绍的是最普通的LSTM,还有其它的LSTM的变种,对内部结构做轻微的改变。
- peephole connections
- Gated Recurrent Unit
- Deep LSTM
写在最后
在一系列RNN取得的优秀成果背后,有相当多使用的是LSTM结构。RNN在训练时会遇到gradient explode/vanishing,导致无法训练。实际中,使用更多的是改良后的LSTM,GRU等。希望上面的拆解使得LSTM看起来平易近人。
LSTM是一个重大的进步,继LSTM之后,还有一个重大的进步,就是Attention,注意力机制。接下来还会更具体地介绍Attention,敬请期待!😘
参考
